分析百度图片请求的参数
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&word="+keyWord+"&pn="+pn+"&rn="+rn+"&width=1920&height=1080&cg=wallpaper
经过删减分析得出关键几个参数
word关键字pn本次请求的初始位置rn当前页最高的数据量width=1920&height=1080&cg=wallpaper这几个参数为图片类型 像素
分析json数据
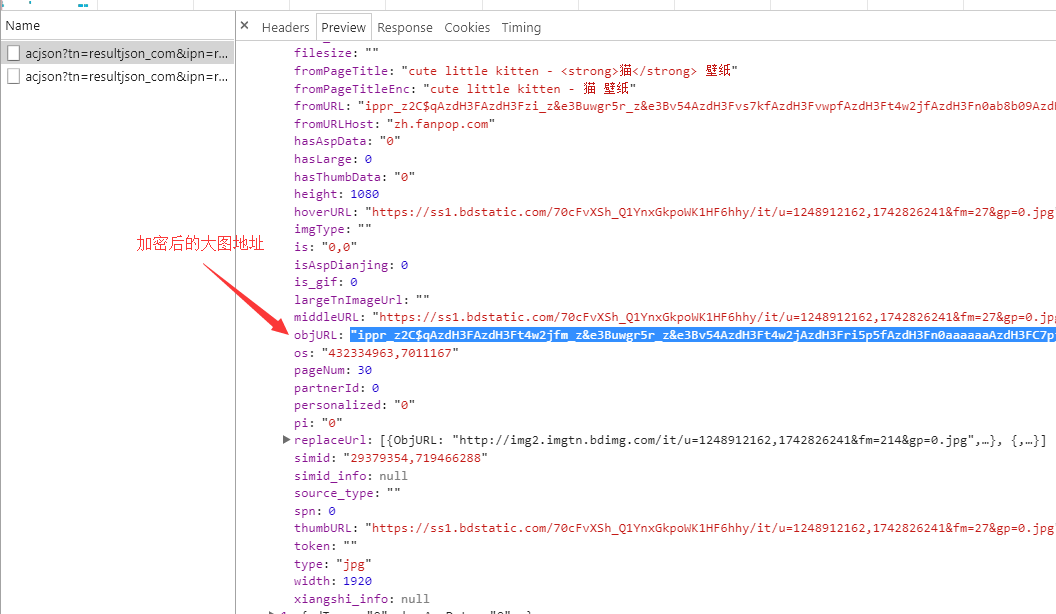
- 很容易看出
type为图片的类型 - 在查找图片大图地址的时候,参考网络上的说明,
objURL即为大图地址,网络上的爬虫也都是直接用的,但是目前来看百度进行了加密处理,查看他的DOM的结构。
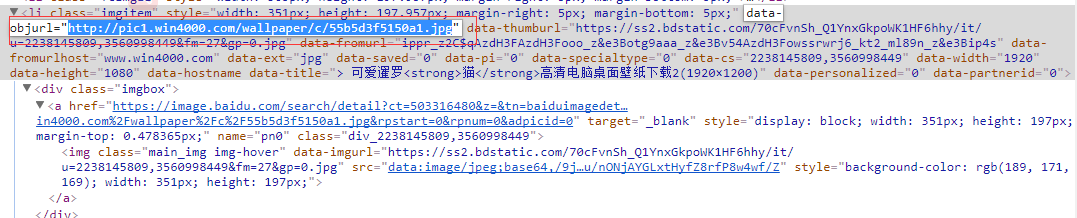
经过尝试红框内即为真实地址,所以猜测他的解密函数应该在本地。并非使用服务器解密。于是尝试寻找解密函数。
在查找的过程中发现图片对应的超链接内也含有真实地址,并且包含其他参数,于是接着寻找
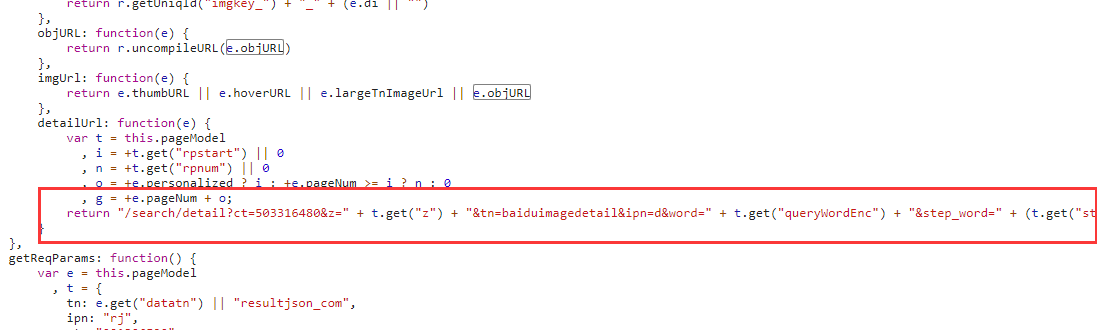
这个地方和a链接地址很相似,于是往后查看真实地址的参数
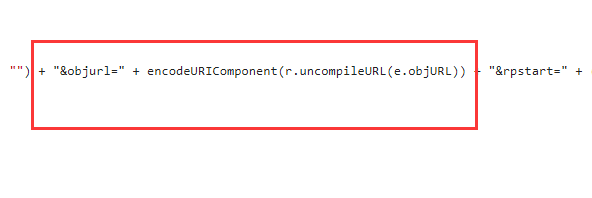
可以看出地址是被处理过的,所以猜测uncompoleURL即为解密函数,接着查找解密函数所在的位置
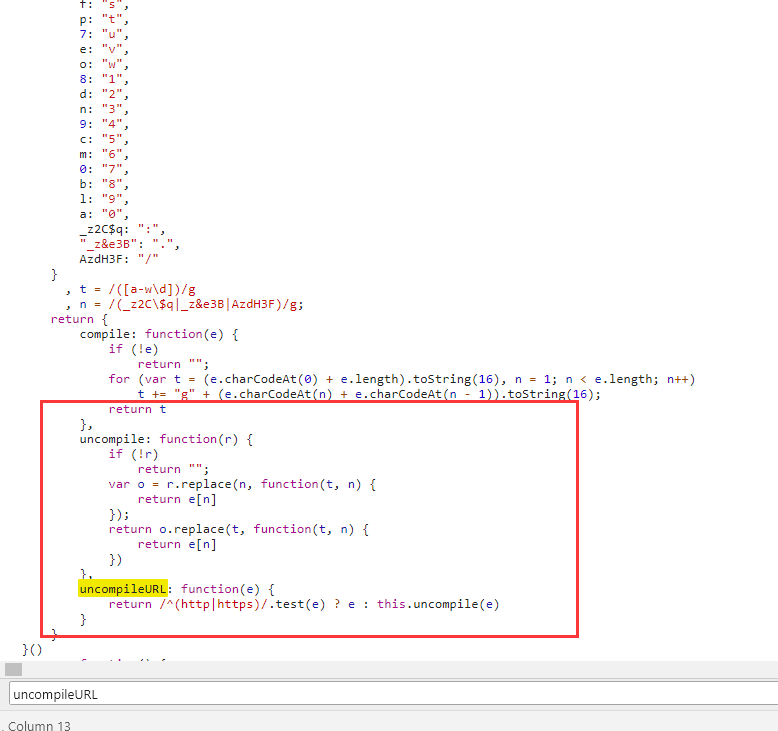
大功告成,解密函数找到了,可以看出加密方式很简单,替换加密。
编写爬虫
const request = require('request');
const fs = require('fs');
const readline = require('readline');
const mkdirp= require('mkdirp');
const async = require('async');
const url = require('url');
// const path = require('path');
// const rp = require('request-promise');
// const cheerio = require('cheerio');
// const readLineSync = require('readline-sync');
/**
*
* 配置信息 后期可通过控制台动态配置
*/
let options = {
keyWord:"猫", // 用于自定义文件标识
maxDown:3 // 最大并行下载量
};
//百度图片解密函数
let jiemi = (function () {
var t = {
w: "a",
k: "b",
v: "c",
1: "d",
j: "e",
u: "f",
2: "g",
i: "h",
t: "i",
3: "j",
h: "k",
s: "l",
4: "m",
g: "n",
5: "o",
r: "p",
q: "q",
6: "r",
f: "s",
p: "t",
7: "u",
e: "v",
o: "w",
8: "1",
d: "2",
n: "3",
9: "4",
c: "5",
m: "6",
0: "7",
b: "8",
l: "9",
a: "0",
_z2C$q: ":",
"_z&e3B": ".",
AzdH3F: "/"
}
, n = /([a-w\d])/g
, i = /(_z2C\$q|_z&e3B|AzdH3F)/g;
return {
compile: function(t) {
if (!t)
return "";
for (var e = (t.charCodeAt(0) + t.length).toString(16), n = 1; n < t.length; n++)
e += "g" + (t.charCodeAt(n) + t.charCodeAt(n - 1)).toString(16);
return e
},
uncompile: function(e) {
if (!e)
return "";
var r = e.replace(i, function(e, n) {
return t[n]
});
return r.replace(n, function(e, n) {
return t[n]
})
},
uncompileURL: function(t) {
return /^(http|https)/.test(t) ? t : this.uncompile(t)
},
trimTags: function(t, n) {
var i = "";
return n && n.length && (i = function(t, i) {
return e.inArray(i, n) < 0 ? "" : t
}
),
String(t).replace(/<\/?([^>]*)>/g, i)
}
}
})();
//控制台接受参数函数
function readSyncByRl(tips) {
tips = tips || '> ';
return new Promise((resolve) => {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
rl.question(tips, (answer) => {
rl.close();
resolve(answer.trim());
});
});
}
readSyncByRl('请输入搜索关键字:').then((keyWord) => {
let pn = 0,
rn=30;
keyWord = encodeURIComponent(keyWord);
let queryUrl = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&word="+keyWord+"&pn="+pn+"&rn="+rn+"&width=1920&height=1080&cg=wallpaper";
request({
url: queryUrl,
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
"X-Requested-With":"XMLHttpRequest"
}
},function (err,res,body) {
if(!err && res.statusCode === 200){
let result = eval('(' + res.body + ')').data,
dir = 'img';
mkdir(dir,result);
}
});
});
/**
* 创建目录
*/
function mkdir(dir,links) {
console.log('准备创建目录:%s', dir);
if (fs.existsSync(dir)) {
console.log('目录:%s 已经存在', dir);
downImages(dir,links);
}else {
mkdirp(dir, function (err) {
console.log('title目录:%s 创建成功', dir);
downImages(dir,links);
});
}
}
/**
* 下载图片
*/
function downImages(dir,links) {
console.log("总共%d张图片,准备下载",links.length);
let errNum = 0;
async.eachOfLimit(links, options.maxDown,function (imgUri,index,cb) {
let relLink = jiemi.uncompileURL(imgUri.objURL);
if(!relLink){
console.error('地址无效');
cb();
}else{
let myURL = url.parse(relLink);
let arr =myURL.pathname.split('/');
let fileName = arr[arr.length-1];
let imgPath = dir+'/'+fileName+'/';
console.log('开始下载图片:%s,保存到:%s', fileName, dir);
request(relLink).on('error', function(err) {
++errNum;
console.log('出错'+errNum+'个');
cb();
}).pipe(fs.createWriteStream(imgPath)).on('finish',()=>{
console.log('图片下载成功:%s', relLink);
cb();})
}
},function (err) {
if(err){
console.log('下载出错,请稍后重试。。。错误信息:'+err.message);
}else {
console.info('下载完成')
}
});
}
- 我们先把百度的解密函数征途复制出来,放到一个自执行的函数中。
- 使用
readline获取用户在控制台输入的关键词。 - 使用
mkdir创建文件目录 - 使用
fs保存文件 - 使用
request请求数据
